Project Alzheimer_SRP3410872_fecal services include NGS sequencing of the V3V4 region of the 16S rRNA gene amplicons from the samples. First and foremost, please
download this report, as well as the sequence raw data from the download links provided below.
These links will expire after 60 days. We cannot guarantee the availability of your data after 60 days.
Full Bioinformatics analysis service was requested. We provide many analyses, starting from the raw sequence quality and noise filtering, pair reads merging, as well as chimera filtering for the sequences, using the
DADA2 denosing algorithm and pipeline.
We also provide many downstream analyses such as taxonomy assignment, alpha and beta diversity analyses, and differential abundance analysis.
For taxonomy assignment, most informative would be the taxonomy barplots. We provide an interactive barplots to show the relative abundance of microbes at different taxonomy levels (from Phylum to species) that you can choose.
If you specify which groups of samples you want to compare for differential abundance, we provide both ANCOM and LEfSe differential abundance analysis.
The samples were processed and analyzed with the ZymoBIOMICS® Service: Targeted
Metagenomic Sequencing (Zymo Research, Irvine, CA).
DNA Extraction: If DNA extraction was performed, one of three different DNA
extraction kits was used depending on the sample type and sample volume and were
used according to the manufacturer’s instructions, unless otherwise stated. The kit used
in this project is marked below:
☑
ZymoBIOMICS®-96 MagBead DNA Kit (Zymo Research, Irvine, CA)
☐
N/A (DNA Extraction Not Performed)
Elution Volume: 50µL
Additional Notes: NA
Targeted Library Preparation: The DNA samples were prepared for targeted
sequencing with the Quick-16S™ NGS Library Prep Kit (Zymo Research, Irvine, CA).
These primers were custom designed by Zymo Research to provide the best coverage
of the 16S gene while maintaining high sensitivity. The primer sets used in this project
are marked below:
☐
Quick-16S™ Primer Set V1-V2 (Zymo Research, Irvine, CA)
☐
Quick-16S™ Primer Set V1-V3 (Zymo Research, Irvine, CA)
☑
Quick-16S™ Primer Set V3-V4 (Zymo Research, Irvine, CA)
☐
Quick-16S™ Primer Set V4 (Zymo Research, Irvine, CA)
☐
Quick-16S™ Primer Set V6-V8 (Zymo Research, Irvine, CA)
☐
Other: NA
Additional Notes: NA
The sequencing library was prepared using an innovative library preparation process in
which PCR reactions were performed in real-time PCR machines to control cycles and
therefore limit PCR chimera formation. The final PCR products were quantified with
qPCR fluorescence readings and pooled together based on equal molarity. The final
pooled library was cleaned up with the Select-a-Size DNA Clean & Concentrator™
(Zymo Research, Irvine, CA), then quantified with TapeStation® (Agilent Technologies,
Santa Clara, CA) and Qubit® (Thermo Fisher Scientific, Waltham, WA).
Control Samples: The ZymoBIOMICS® Microbial Community Standard (Zymo
Research, Irvine, CA) was used as a positive control for each DNA extraction, if
performed. The ZymoBIOMICS® Microbial Community DNA Standard (Zymo Research,
Irvine, CA) was used as a positive control for each targeted library preparation.
Negative controls (i.e. blank extraction control, blank library preparation control) were
included to assess the level of bioburden carried by the wet-lab process.
Sequencing: The final library was sequenced on Illumina® MiSeq™ with a V3 reagent kit
(600 cycles). The sequencing was performed with 10% PhiX spike-in.
Absolute Abundance Quantification*: A quantitative real-time PCR was set up with a
standard curve. The standard curve was made with plasmid DNA containing one copy
of the 16S gene and one copy of the fungal ITS2 region prepared in 10-fold serial
dilutions. The primers used were the same as those used in Targeted Library
Preparation. The equation generated by the plasmid DNA standard curve was used to
calculate the number of gene copies in the reaction for each sample. The PCR input
volume (2 µl) was used to calculate the number of gene copies per microliter in each
DNA sample.
The number of genome copies per microliter DNA sample was calculated by dividing
the gene copy number by an assumed number of gene copies per genome. The value
used for 16S copies per genome is 4. The value used for ITS copies per genome is 200.
The amount of DNA per microliter DNA sample was calculated using an assumed
genome size of 4.64 x 106 bp, the genome size of Escherichia coli, for 16S samples, or
an assumed genome size of 1.20 x 107 bp, the genome size of Saccharomyces
cerevisiae, for ITS samples. This calculation is shown below:
Calculated Total DNA = Calculated Total Genome Copies × Assumed Genome Size (4.64 × 106 bp) ×
Average Molecular Weight of a DNA bp (660 g/mole/bp) ÷ Avogadro’s Number (6.022 x 1023/mole)
* Absolute Abundance Quantification is only available for 16S and ITS analyses.
The absolute abundance standard curve data can be viewed in Excel here:
The absolute abundance standard curve is shown below:
The complete report of your project, including all links in this report, can be downloaded by clicking the link provided below. The downloaded file is a compressed ZIP file and once unzipped, open the file “REPORT.html” (may only shown as "REPORT" in your computer) by double clicking it. Your default web browser will open it and you will see the exact content of this report.
Please download and save the file to your computer storage device. The download link will expire after 60 days upon your receiving of this report.
Complete report download link:
To view the report, please follow the following steps:
1.
Download the .zip file from the report link above.
2.
Extract all the contents of the downloaded .zip file to your desktop.
3.
Open the extracted folder and find the "REPORT.html" (may shown as only "REPORT").
4.
Open (double-clicking) the REPORT.html file. Your default browser will open the top age of the complete report. Within the
report, there are links to view all the analyses performed for the project.
The raw NGS sequence data is available for download with the link provided below. The data is a compressed ZIP file and can be unzipped to individual sequence files.
Since this is a Pac-Bio full-length (V1V9) 16S rRNA amplicon sequencing, raw sequences are available for download in a single compressed zip file in the download link below.
After unzipping, you will find individual sequence files for each of your samples with the file extension “*.fastq.gz”.
The files are in FASTQ format and are compressed. FASTQ format is a text-based data format for storing both a biological sequence
and its corresponding quality scores. Most sequence analysis software will be able to open them.
The Sample IDs associated with the fastq files are listed in the table below:
Sample ID
Original Sample ID
Read 1 File Name
Read 2 File Name
F3410872.S01
fastq_ori/SRR16303365_1.fastq
fastq_ori/SRR16303365_2.fastq
F3410872.S02
fastq_ori/SRR16303453_1.fastq
fastq_ori/SRR16303453_2.fastq
F3410872.S03
fastq_ori/SRR16303454_1.fastq
fastq_ori/SRR16303454_2.fastq
F3410872.S04
fastq_ori/SRR16303455_1.fastq
fastq_ori/SRR16303455_2.fastq
F3410872.S05
fastq_ori/SRR16303456_1.fastq
fastq_ori/SRR16303456_2.fastq
F3410872.S06
fastq_ori/SRR16303457_1.fastq
fastq_ori/SRR16303457_2.fastq
F3410872.S07
fastq_ori/SRR16303458_1.fastq
fastq_ori/SRR16303458_2.fastq
F3410872.S08
fastq_ori/SRR16303459_1.fastq
fastq_ori/SRR16303459_2.fastq
F3410872.S09
fastq_ori/SRR16303460_1.fastq
fastq_ori/SRR16303460_2.fastq
F3410872.S10
fastq_ori/SRR16303462_1.fastq
fastq_ori/SRR16303462_2.fastq
F3410872.S11
fastq_ori/SRR16303463_1.fastq
fastq_ori/SRR16303463_2.fastq
F3410872.S12
fastq_ori/SRR16303464_1.fastq
fastq_ori/SRR16303464_2.fastq
F3410872.S13
fastq_ori/SRR16303465_1.fastq
fastq_ori/SRR16303465_2.fastq
F3410872.S14
fastq_ori/SRR16303466_1.fastq
fastq_ori/SRR16303466_2.fastq
F3410872.S15
fastq_ori/SRR16303467_1.fastq
fastq_ori/SRR16303467_2.fastq
F3410872.S16
fastq_ori/SRR16303468_1.fastq
fastq_ori/SRR16303468_2.fastq
F3410872.S17
fastq_ori/SRR16303469_1.fastq
fastq_ori/SRR16303469_2.fastq
F3410872.S18
fastq_ori/SRR16303470_1.fastq
fastq_ori/SRR16303470_2.fastq
F3410872.S19
fastq_ori/SRR16303471_1.fastq
fastq_ori/SRR16303471_2.fastq
F3410872.S20
fastq_ori/SRR16303473_1.fastq
fastq_ori/SRR16303473_2.fastq
F3410872.S21
fastq_ori/SRR16303474_1.fastq
fastq_ori/SRR16303474_2.fastq
F3410872.S22
fastq_ori/SRR16303475_1.fastq
fastq_ori/SRR16303475_2.fastq
F3410872.S23
fastq_ori/SRR16303476_1.fastq
fastq_ori/SRR16303476_2.fastq
F3410872.S24
fastq_ori/SRR16303477_1.fastq
fastq_ori/SRR16303477_2.fastq
F3410872.S25
fastq_ori/SRR16303478_1.fastq
fastq_ori/SRR16303478_2.fastq
F3410872.S26
fastq_ori/SRR16303479_1.fastq
fastq_ori/SRR16303479_2.fastq
F3410872.S27
fastq_ori/SRR16303480_1.fastq
fastq_ori/SRR16303480_2.fastq
F3410872.S28
fastq_ori/SRR16303481_1.fastq
fastq_ori/SRR16303481_2.fastq
F3410872.S29
fastq_ori/SRR16303482_1.fastq
fastq_ori/SRR16303482_2.fastq
F3410872.S30
fastq_ori/SRR16303484_1.fastq
fastq_ori/SRR16303484_2.fastq
F3410872.S31
fastq_ori/SRR16303485_1.fastq
fastq_ori/SRR16303485_2.fastq
F3410872.S32
fastq_ori/SRR16303486_1.fastq
fastq_ori/SRR16303486_2.fastq
F3410872.S33
fastq_ori/SRR16303487_1.fastq
fastq_ori/SRR16303487_2.fastq
F3410872.S34
fastq_ori/SRR16303488_1.fastq
fastq_ori/SRR16303488_2.fastq
F3410872.S35
fastq_ori/SRR16303489_1.fastq
fastq_ori/SRR16303489_2.fastq
F3410872.S36
fastq_ori/SRR16303490_1.fastq
fastq_ori/SRR16303490_2.fastq
F3410872.S37
fastq_ori/SRR16303491_1.fastq
fastq_ori/SRR16303491_2.fastq
F3410872.S38
fastq_ori/SRR16303492_1.fastq
fastq_ori/SRR16303492_2.fastq
F3410872.S39
fastq_ori/SRR16303493_1.fastq
fastq_ori/SRR16303493_2.fastq
F3410872.S40
fastq_ori/SRR16303495_1.fastq
fastq_ori/SRR16303495_2.fastq
F3410872.S41
fastq_ori/SRR16303496_1.fastq
fastq_ori/SRR16303496_2.fastq
F3410872.S42
fastq_ori/SRR16303497_1.fastq
fastq_ori/SRR16303497_2.fastq
F3410872.S43
fastq_ori/SRR16303498_1.fastq
fastq_ori/SRR16303498_2.fastq
F3410872.S44
fastq_ori/SRR16303499_1.fastq
fastq_ori/SRR16303499_2.fastq
F3410872.S45
fastq_ori/SRR16303500_1.fastq
fastq_ori/SRR16303500_2.fastq
F3410872.S46
fastq_ori/SRR16303501_1.fastq
fastq_ori/SRR16303501_2.fastq
F3410872.S47
fastq_ori/SRR16303502_1.fastq
fastq_ori/SRR16303502_2.fastq
F3410872.S48
fastq_ori/SRR16303503_1.fastq
fastq_ori/SRR16303503_2.fastq
F3410872.S49
fastq_ori/SRR16303504_1.fastq
fastq_ori/SRR16303504_2.fastq
F3410872.S50
fastq_ori/SRR16303506_1.fastq
fastq_ori/SRR16303506_2.fastq
F3410872.S51
fastq_ori/SRR16303507_1.fastq
fastq_ori/SRR16303507_2.fastq
F3410872.S52
fastq_ori/SRR16303508_1.fastq
fastq_ori/SRR16303508_2.fastq
F3410872.S53
fastq_ori/SRR16303509_1.fastq
fastq_ori/SRR16303509_2.fastq
F3410872.S54
fastq_ori/SRR16303510_1.fastq
fastq_ori/SRR16303510_2.fastq
F3410872.S55
fastq_ori/SRR16303511_1.fastq
fastq_ori/SRR16303511_2.fastq
F3410872.S56
fastq_ori/SRR16303512_1.fastq
fastq_ori/SRR16303512_2.fastq
F3410872.S57
fastq_ori/SRR16303513_1.fastq
fastq_ori/SRR16303513_2.fastq
F3410872.S58
fastq_ori/SRR16303514_1.fastq
fastq_ori/SRR16303514_2.fastq
F3410872.S59
fastq_ori/SRR16303515_1.fastq
fastq_ori/SRR16303515_2.fastq
F3410872.S60
fastq_ori/SRR16303517_1.fastq
fastq_ori/SRR16303517_2.fastq
F3410872.S61
fastq_ori/SRR16303518_1.fastq
fastq_ori/SRR16303518_2.fastq
F3410872.S62
fastq_ori/SRR16303520_1.fastq
fastq_ori/SRR16303520_2.fastq
F3410872.S63
fastq_ori/SRR16303521_1.fastq
fastq_ori/SRR16303521_2.fastq
F3410872.S64
fastq_ori/SRR16303522_1.fastq
fastq_ori/SRR16303522_2.fastq
F3410872.S65
fastq_ori/SRR16303523_1.fastq
fastq_ori/SRR16303523_2.fastq
F3410872.S66
fastq_ori/SRR16303524_1.fastq
fastq_ori/SRR16303524_2.fastq
F3410872.S67
fastq_ori/SRR16303525_1.fastq
fastq_ori/SRR16303525_2.fastq
F3410872.S68
fastq_ori/SRR16303526_1.fastq
fastq_ori/SRR16303526_2.fastq
F3410872.S69
fastq_ori/SRR16303528_1.fastq
fastq_ori/SRR16303528_2.fastq
F3410872.S70
fastq_ori/SRR16303529_1.fastq
fastq_ori/SRR16303529_2.fastq
F3410872.S71
fastq_ori/SRR16303530_1.fastq
fastq_ori/SRR16303530_2.fastq
F3410872.S72
fastq_ori/SRR16303531_1.fastq
fastq_ori/SRR16303531_2.fastq
F3410872.S73
fastq_ori/SRR16303532_1.fastq
fastq_ori/SRR16303532_2.fastq
F3410872.S74
fastq_ori/SRR16303533_1.fastq
fastq_ori/SRR16303533_2.fastq
F3410872.S75
fastq_ori/SRR16303534_1.fastq
fastq_ori/SRR16303534_2.fastq
F3410872.S76
fastq_ori/SRR16303535_1.fastq
fastq_ori/SRR16303535_2.fastq
F3410872.S77
fastq_ori/SRR16303536_1.fastq
fastq_ori/SRR16303536_2.fastq
F3410872.S78
fastq_ori/SRR16303537_1.fastq
fastq_ori/SRR16303537_2.fastq
F3410872.S79
fastq_ori/SRR16303539_1.fastq
fastq_ori/SRR16303539_2.fastq
F3410872.S80
fastq_ori/SRR16303540_1.fastq
fastq_ori/SRR16303540_2.fastq
F3410872.S81
fastq_ori/SRR16303541_1.fastq
fastq_ori/SRR16303541_2.fastq
F3410872.S82
fastq_ori/SRR16303542_1.fastq
fastq_ori/SRR16303542_2.fastq
F3410872.S83
fastq_ori/SRR16303543_1.fastq
fastq_ori/SRR16303543_2.fastq
F3410872.S84
fastq_ori/SRR16303544_1.fastq
fastq_ori/SRR16303544_2.fastq
F3410872.S85
fastq_ori/SRR16303545_1.fastq
fastq_ori/SRR16303545_2.fastq
F3410872.S86
fastq_ori/SRR16303546_1.fastq
fastq_ori/SRR16303546_2.fastq
F3410872.S87
fastq_ori/SRR16303547_1.fastq
fastq_ori/SRR16303547_2.fastq
F3410872.S88
fastq_ori/SRR16303548_1.fastq
fastq_ori/SRR16303548_2.fastq
F3410872.S89
fastq_ori/SRR16303550_1.fastq
fastq_ori/SRR16303550_2.fastq
F3410872.S90
fastq_ori/SRR16303551_1.fastq
fastq_ori/SRR16303551_2.fastq
F3410872.S91
fastq_ori/SRR16303552_1.fastq
fastq_ori/SRR16303552_2.fastq
F3410872.S92
fastq_ori/SRR16303553_1.fastq
fastq_ori/SRR16303553_2.fastq
F3410872.S93
fastq_ori/SRR16303554_1.fastq
fastq_ori/SRR16303554_2.fastq
F3410872.S94
fastq_ori/SRR16303555_1.fastq
fastq_ori/SRR16303555_2.fastq
F3410872.S95
fastq_ori/SRR16303556_1.fastq
fastq_ori/SRR16303556_2.fastq
F3410872.S96
fastq_ori/SRR16303557_1.fastq
fastq_ori/SRR16303557_2.fastq
F3410872.S97
fastq_ori/SRR16303558_1.fastq
fastq_ori/SRR16303558_2.fastq
F3410872.S98
fastq_ori/SRR16303559_1.fastq
fastq_ori/SRR16303559_2.fastq
Please download and save the file to your computer storage device. The download link will expire after 60 days upon your receiving of this report.
DADA2 is a software package that models and corrects Illumina-sequenced amplicon errors [1].
DADA2 infers sample sequences exactly, without coarse-graining into OTUs,
and resolves differences of as little as one nucleotide. DADA2 identified more real variants
and output fewer spurious sequences than other methods.
DADA2’s advantage is that it uses more of the data. The DADA2 error model incorporates quality information,
which is ignored by all other methods after filtering. The DADA2 error model incorporates quantitative abundances,
whereas most other methods use abundance ranks if they use abundance at all.
The DADA2 error model identifies the differences between sequences, eg. A->C,
whereas other methods merely count the mismatches. DADA2 can parameterize its error model from the data itself,
rather than relying on previous datasets that may or may not reflect the PCR and sequencing protocols used in your study.
Callahan BJ, McMurdie PJ, Rosen MJ, Han AW, Johnson AJ, Holmes SP. DADA2: High-resolution sample inference from Illumina amplicon data. Nat Methods. 2016 Jul;13(7):581-3. doi: 10.1038/nmeth.3869. Epub 2016 May 23. PMID: 27214047; PMCID: PMC4927377.
Analysis Procedures:
DADA2 pipeline includes several tools for read quality control, including quality filtering, trimming, denoising, pair merging and chimera filtering. Below are the major processing steps of DADA2:
Step 1. Read trimming based on sequence quality
The quality of NGS Illumina sequences often decreases toward the end of the reads.
DADA2 allows to trim off the poor quality read ends in order to improve the error
model building and pair mergicing performance.
Step 2. Learn the Error Rates
The DADA2 algorithm makes use of a parametric error model (err) and every
amplicon dataset has a different set of error rates. The learnErrors method
learns this error model from the data, by alternating estimation of the error
rates and inference of sample composition until they converge on a jointly
consistent solution. As in many machine-learning problems, the algorithm must
begin with an initial guess, for which the maximum possible error rates in
this data are used (the error rates if only the most abundant sequence is
correct and all the rest are errors).
Step 3. Infer amplicon sequence variants (ASVs) based on the error model built in previous step. This step is also called sequence "denoising".
The outcome of this step is a list of ASVs that are the equivalent of oligonucleotides.
Step 4. Merge paired reads. If the sequencing products are read pairs, DADA2 will merge the R1 and R2 ASVs into single sequences.
Merging is performed by aligning the denoised forward reads with the reverse-complement of the corresponding
denoised reverse reads, and then constructing the merged “contig” sequences.
By default, merged sequences are only output if the forward and reverse reads overlap by
at least 12 bases, and are identical to each other in the overlap region (but these conditions can be changed via function arguments).
Step 5. Remove chimera.
The core dada method corrects substitution and indel errors, but chimeras remain. Fortunately, the accuracy of sequence variants
after denoising makes identifying chimeric ASVs simpler than when dealing with fuzzy OTUs.
Chimeric sequences are identified if they can be exactly reconstructed by
combining a left-segment and a right-segment from two more abundant “parent” sequences. The frequency of chimeric sequences varies substantially
from dataset to dataset, and depends on on factors including experimental procedures and sample complexity.
Results
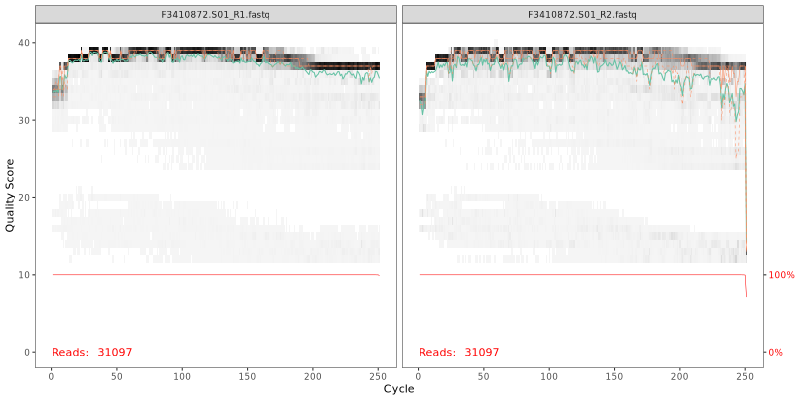
1. Read Quality Plots NGS sequence analaysis starts with visualizing the quality of the sequencing. Below are the quality plots of the first
sample for the R1 and R2 reads separately. In gray-scale is a heat map of the frequency of each quality score at each base position. The mean
quality score at each position is shown by the green line, and the quartiles of the quality score distribution by the orange lines.
The forward reads are usually of better quality. It is a common practice to trim the last few nucleotides to avoid less well-controlled errors
that can arise there. The trimming affects the downstream steps including error model building, merging and chimera calling. FOMC uses an empirical
approach to test many combinations of different trim length in order to achieve best final amplicon sequence variants (ASVs), see the next
section “Optimal trim length for ASVs”.
2. Optimal trim length for ASVs The final number of merged and chimera-filtered ASVs depends on the quality filtering (hence trimming) in the very beginning of the DADA2 pipeline.
In order to achieve highest number of ASVs, an empirical approach was used -
Create a random subset of each sample consisting of 5,000 R1 and 5,000 R2 (to reduce computation time)
Trim 10 bases at a time from the ends of both R1 and R2 up to 50 bases
For each combination of trimmed length (e.g., 300x300, 300x290, 290x290 etc), the trimmed reads are
subject to the entire DADA2 pipeline for chimera-filtered merged ASVs
The combination with highest percentage of the input reads becoming final ASVs is selected for the complete set of data
Below is the result of such operation, showing ASV percentages of total reads for all trimming combinations (1st Column = R1 lengths in bases; 1st Row = R2 lengths in bases):
R1/R2
251
241
231
221
211
201
251
63.34%
82.42%
82.82%
82.82%
82.83%
82.56%
241
63.68%
83.27%
83.69%
83.69%
83.68%
83.40%
231
64.24%
83.92%
84.36%
84.38%
84.40%
84.12%
221
64.03%
83.72%
84.15%
84.21%
84.24%
84.03%
211
63.72%
83.30%
83.70%
83.71%
83.76%
83.68%
201
63.23%
82.63%
83.02%
83.14%
83.20%
83.20%
Based on the above result, the trim length combination of R1 = 231 bases and R2 = 211 bases (highlighted red above), was chosen for generating final ASVs for all sequences.
This combination generated highest number of merged non-chimeric ASVs and was used for downstream analyses, if requested.
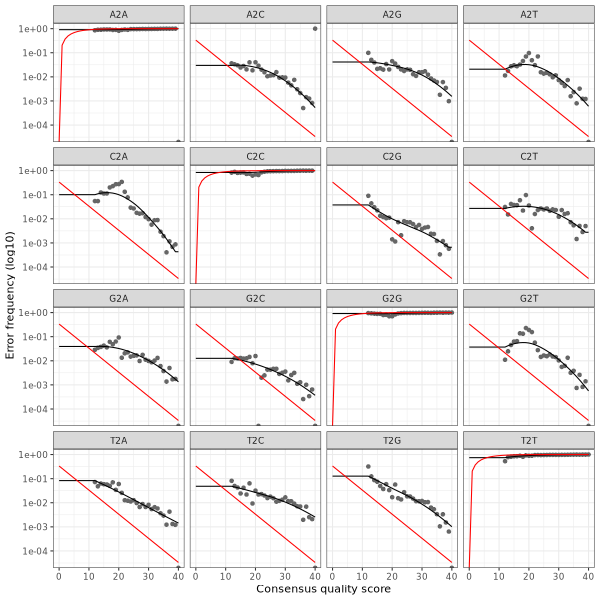
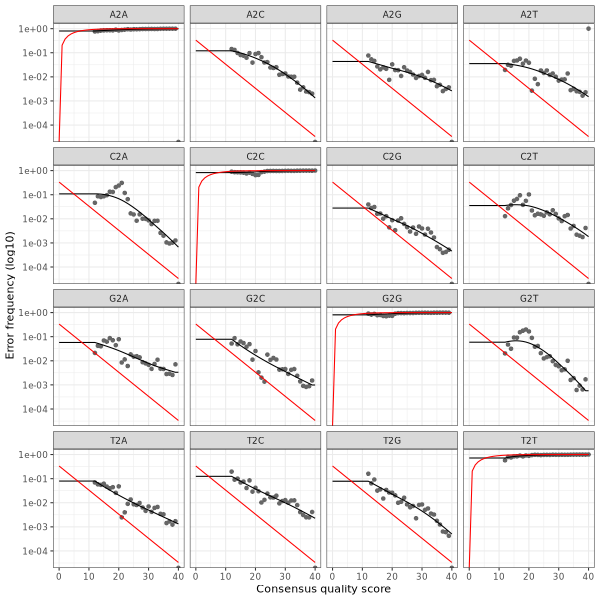
3. Error plots from learning the error rates
After DADA2 building the error model for the set of data, it is always worthwhile, as a sanity check if nothing else, to visualize the estimated error rates.
The error rates for each possible transition (A→C, A→G, …) are shown below. Points are the observed error rates for each consensus quality score.
The black line shows the estimated error rates after convergence of the machine-learning algorithm.
The red line shows the error rates expected under the nominal definition of the Q-score.
The ideal result would be the estimated error rates (black line) are a good fit to the observed rates (points), and the error rates drop
with increased quality as expected.
Forward Read R1 Error Plot
Reverse Read R2 Error Plot
The PDF version of these plots are available here:
4. DADA2 Result Summary The table below shows the summary of the DADA2 analysis,
tracking paired read counts of each samples for all the steps during DADA2 denoising process -
including end-trimming (filtered), denoising (denoisedF, denoisedF), pair merging (merged) and chimera removal (nonchim).
Sample ID
F3410872.S01
F3410872.S02
F3410872.S03
F3410872.S04
F3410872.S05
F3410872.S06
F3410872.S07
F3410872.S08
F3410872.S09
F3410872.S10
F3410872.S11
F3410872.S12
F3410872.S13
F3410872.S14
F3410872.S15
F3410872.S16
F3410872.S17
F3410872.S18
F3410872.S19
F3410872.S20
F3410872.S21
F3410872.S22
F3410872.S23
F3410872.S24
F3410872.S25
F3410872.S26
F3410872.S27
F3410872.S28
F3410872.S29
F3410872.S30
F3410872.S31
F3410872.S32
F3410872.S33
F3410872.S34
F3410872.S35
F3410872.S36
F3410872.S37
F3410872.S38
F3410872.S39
F3410872.S40
F3410872.S41
F3410872.S42
F3410872.S43
F3410872.S44
F3410872.S45
F3410872.S46
F3410872.S47
F3410872.S48
F3410872.S49
F3410872.S50
F3410872.S51
F3410872.S52
F3410872.S53
F3410872.S54
F3410872.S55
F3410872.S56
F3410872.S57
F3410872.S58
F3410872.S59
F3410872.S60
F3410872.S61
F3410872.S62
F3410872.S63
F3410872.S64
F3410872.S65
F3410872.S66
F3410872.S67
F3410872.S68
F3410872.S69
F3410872.S70
F3410872.S71
F3410872.S72
F3410872.S73
F3410872.S74
F3410872.S75
F3410872.S76
F3410872.S77
F3410872.S78
F3410872.S79
F3410872.S80
F3410872.S81
F3410872.S82
F3410872.S83
F3410872.S84
F3410872.S85
F3410872.S86
F3410872.S87
F3410872.S88
F3410872.S89
F3410872.S90
F3410872.S91
F3410872.S92
F3410872.S93
F3410872.S94
F3410872.S95
F3410872.S96
F3410872.S97
F3410872.S98
Row Sum
Percentage
input
31,097
42,868
47,705
35,670
42,396
42,334
36,938
48,877
18,110
49,874
48,910
43,966
33,558
38,494
49,413
48,824
37,755
46,802
22,821
47,840
28,381
44,790
21,483
48,950
38,107
35,646
23,747
49,526
6,660
36,700
28,506
43,977
25,960
24,707
23,507
21,833
18,979
27,338
23,312
35,709
17,528
20,142
29,839
28,006
33,938
24,287
32,573
43,150
25,426
33,470
23,428
28,108
25,411
25,684
22,098
22,570
23,693
21,570
37,872
31,810
26,586
18,041
33,661
23,966
26,878
29,687
29,927
35,843
41,995
19,552
28,105
47,578
24,394
39,575
24,855
31,535
12,133
28,112
29,052
26,761
12,131
48,349
24,860
37,381
37,656
2,730
12,773
27,246
31,702
19,117
28,821
36,621
33,613
27,629
21,465
27,826
41,841
51,275
3,073,945
100.00%
filtered
31,097
42,868
47,705
35,670
42,396
42,334
36,938
48,876
18,110
49,873
48,910
43,966
33,558
38,493
49,411
48,824
37,753
46,802
22,821
47,840
28,381
44,790
21,483
48,949
38,107
35,645
23,746
49,525
6,660
36,699
28,506
43,977
25,959
24,705
23,507
21,832
18,979
27,338
23,312
35,708
17,528
20,142
29,839
28,006
33,938
24,286
32,573
43,150
25,425
33,469
23,428
28,108
25,411
25,684
22,098
22,569
23,693
21,569
37,872
31,810
26,586
18,041
33,661
23,966
26,878
29,687
29,927
35,842
41,994
19,552
28,105
47,578
24,394
39,575
24,855
31,535
12,133
28,111
29,052
26,760
12,131
48,349
24,860
37,381
37,656
2,730
12,773
27,246
31,702
19,117
28,819
36,621
33,613
27,629
21,465
27,826
41,841
51,275
3,073,917
100.00%
denoisedF
30,002
41,850
46,635
34,959
41,259
41,386
35,899
47,872
17,600
48,860
47,827
42,784
32,414
37,431
48,348
47,579
36,687
45,709
22,296
47,010
27,329
43,646
20,635
48,178
36,962
34,631
23,136
48,099
6,416
35,265
27,811
43,591
25,167
23,663
22,908
21,173
18,245
26,676
22,714
34,829
17,235
19,545
28,888
27,073
33,243
23,740
31,969
42,172
24,371
32,598
22,591
27,066
24,398
24,893
21,562
21,779
23,180
21,016
37,013
30,849
25,571
17,507
32,602
23,272
25,907
28,689
28,902
34,797
40,790
19,047
27,344
46,855
23,851
37,958
24,144
31,084
11,733
27,269
27,909
26,292
11,695
47,289
23,686
36,875
36,709
2,595
12,398
26,483
30,952
18,210
27,931
35,841
32,461
26,673
20,808
27,156
40,571
50,486
2,991,004
97.30%
denoisedR
29,961
41,873
46,560
34,803
41,248
41,516
35,830
47,877
17,550
48,535
47,717
42,660
32,569
37,379
48,240
47,474
36,582
44,903
22,285
46,932
27,347
43,558
20,532
48,130
36,809
34,424
23,104
48,032
6,423
35,317
27,834
43,512
25,286
23,627
22,935
21,184
18,204
26,263
22,585
34,732
17,260
19,489
28,913
27,038
33,128
23,580
31,860
42,079
24,294
32,543
22,583
27,012
24,337
24,985
21,632
21,283
23,203
21,064
36,935
30,837
25,422
17,367
32,603
23,164
25,748
28,528
28,945
34,808
40,141
18,953
27,302
46,775
23,735
38,146
24,125
31,000
11,673
27,205
28,005
26,196
11,515
47,341
23,743
36,801
36,801
2,616
12,417
26,421
30,775
18,270
27,874
35,805
32,480
26,606
20,816
27,047
40,666
50,071
2,984,293
97.08%
merged
27,450
39,919
44,418
33,097
38,665
39,919
32,298
45,786
16,572
43,509
44,806
40,166
29,785
35,717
46,365
43,465
33,758
30,396
21,377
45,783
25,562
40,740
19,324
46,713
34,580
31,812
20,211
44,994
6,147
32,925
26,581
42,914
24,233
21,690
21,866
19,910
17,100
21,316
21,129
33,359
16,840
18,650
27,216
24,702
31,954
22,414
30,120
39,589
22,474
30,051
20,990
25,519
22,535
23,551
20,526
19,838
22,525
20,178
34,577
29,179
22,785
15,727
30,373
20,892
23,837
26,746
26,657
32,794
28,416
18,303
25,547
45,777
22,841
35,327
22,761
29,902
11,036
24,446
25,986
24,751
10,414
45,632
21,732
35,496
35,412
2,514
12,052
25,201
29,373
17,139
26,385
34,076
30,632
24,430
19,756
25,592
38,318
46,912
2,785,755
90.62%
nonchim
23,685
34,388
40,971
28,002
34,199
34,304
28,384
40,325
14,656
38,105
40,032
34,138
26,228
32,175
42,271
35,355
29,987
26,553
17,301
41,759
22,977
33,484
18,485
35,707
30,683
26,483
18,670
38,498
6,019
30,256
23,161
41,239
19,579
19,597
17,845
17,210
15,315
19,353
17,844
32,202
14,361
15,493
22,545
23,036
28,188
18,700
24,281
34,858
20,929
27,154
17,979
22,803
20,242
20,802
17,335
17,270
19,711
17,620
30,032
24,824
20,513
13,447
24,821
18,611
22,067
22,832
23,232
27,155
26,447
17,244
21,989
42,018
18,803
30,205
20,123
25,532
10,019
20,295
23,209
22,143
8,585
41,347
19,822
29,741
32,446
2,485
11,679
22,483
26,277
15,169
24,012
27,758
25,892
22,195
17,687
21,584
33,552
38,061
2,437,068
79.28%
This table can be downloaded as an Excel table below:
5. DADA2 Amplicon Sequence Variants (ASVs). A total of 2634 unique merged and chimera-free ASV sequences were identified, and their corresponding
read counts for each sample are available in the "ASV Read Count Table" with rows for the ASV sequences and columns for sample. This read count table can be used for
microbial profile comparison among different samples and the sequences provided in the table can be used to taxonomy assignment.
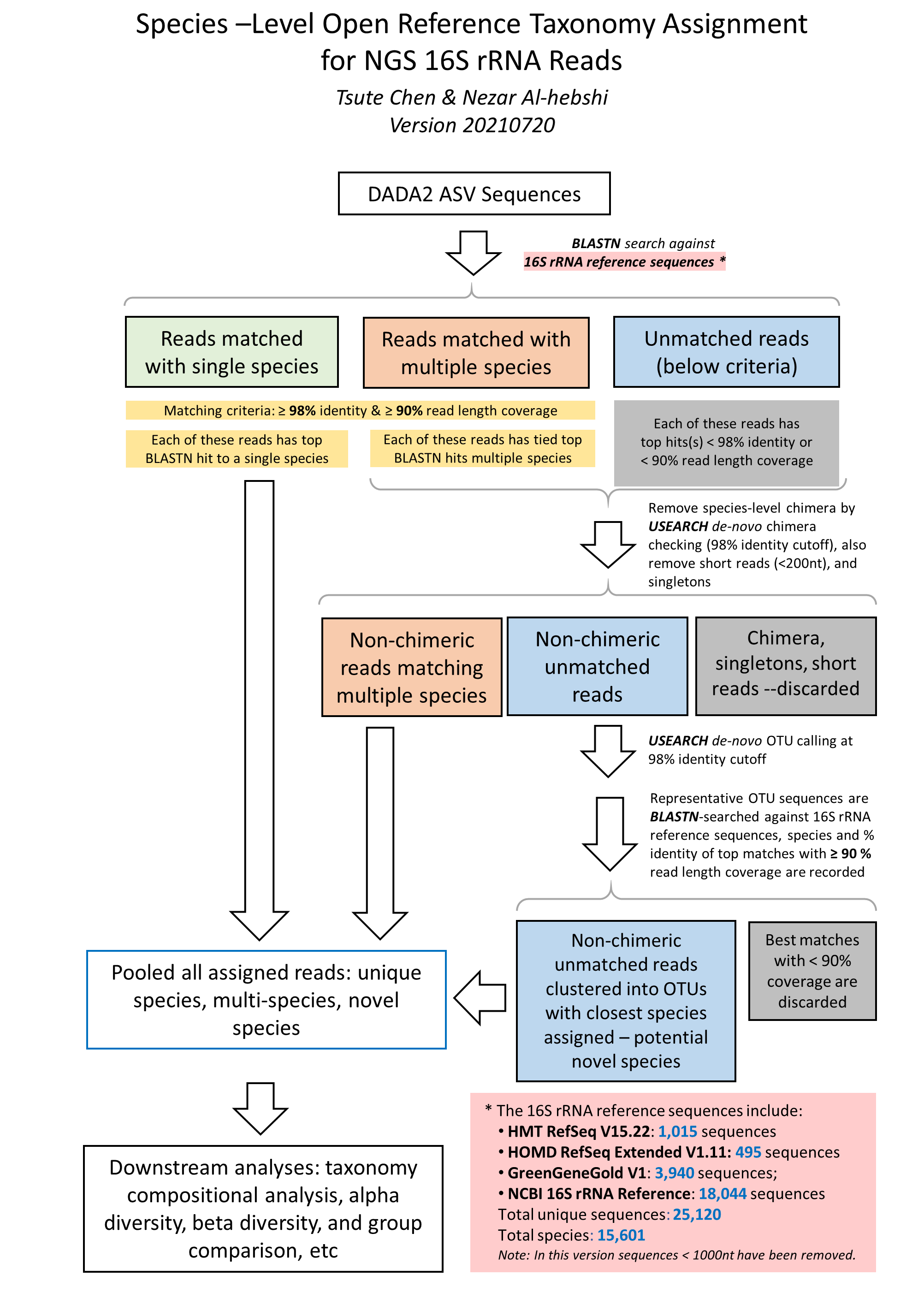
The species-level, open-reference 16S rRNA NGS reads taxonomy assignment pipeline
Version 20210310a
The close-reference taxonomy assignment of the ASV sequences using BLASTN is based on the algorithm published by Al-Hebshi et. al. (2015)[2].
1. Raw sequences reads in FASTA format were BLASTN-searched against a combined set of 16S rRNA reference sequences - the FOMC 16S rRNA Reference Sequences version 20221029 (https://microbiome.forsyth.org/ftp/refseq/).
This set consists of the HOMD (version 15.22 http://www.homd.org/index.php?name=seqDownload&file&type=R ), Mouse Oral Microbiome Database (MOMD version 5.1 https://momd.org/ftp/16S_rRNA_refseq/MOMD_16S_rRNA_RefSeq/V5.1/),
and the NCBI 16S rRNA reference sequence set (https://ftp.ncbi.nlm.nih.gov/blast/db/16S_ribosomal_RNA.tar.gz).
These sequences were screened and combined to remove short sequences (<1000nt), chimera, duplicated and sub-sequences,
as well as sequences with poor taxonomy annotation (e.g., without species information).
This process resulted in 1,015 full-length 16S rRNA sequences from HOMD V15.22, 356 from MOMD V5.1, and 22,126 from NCBI, a total of 23,497 sequences.
Altogether these sequence represent a total of 17,035 oral and non-oral microbial species.
The NCBI BLASTN version 2.7.1+ (Zhang et al, 2000) [3] was used with the default parameters.
Reads with ≥ 98% sequence identity to the matched reference and ≥ 90% alignment length
(i.e., ≥ 90% of the read length that was aligned to the reference and was used to calculate
the sequence percent identity) were classified based on the taxonomy of the reference sequence
with highest sequence identity. If a read matched with reference sequences representing
more than one species with equal percent identity and alignment length, it was subject
to chimera checking with USEARCH program version v8.1.1861 (Edgar 2010). Non-chimeric reads with multi-species
best hits were considered valid and were assigned with a unique species
notation (e.g., spp) denoting unresolvable multiple species.
2. Unassigned reads (i.e., reads with < 98% identity or < 90% alignment length) were pooled together and reads < 200 bases were
removed. The remaining reads were subject to the de novo
operational taxonomy unit (OTU) calling and chimera checking using the USEARCH program version v8.1.1861 (Edgar 2010)[4].
The de novo OTU calling and chimera checking was done using 98% as the sequence identity cutoff, i.e., the species-level OTU.
The output of this step produced species-level de novo clustered OTUs with 98% identity.
Representative reads from each of the OTUs/species were then BLASTN-searched
against the same reference sequence set again to determine the closest species for
these potential novel species. These potential novel species were pooled together with the reads that were signed to specie-level in
the previous step, for down-stream analyses.
Reference:
Al-Hebshi NN, Nasher AT, Idris AM, Chen T. Robust species taxonomy assignment algorithm for 16S rRNA NGS reads: application
to oral carcinoma samples. J Oral Microbiol. 2015 Sep 29;7:28934. doi: 10.3402/jom.v7.28934. PMID: 26426306; PMCID: PMC4590409.
Zhang Z, Schwartz S, Wagner L, Miller W. A greedy algorithm for aligning DNA sequences. J Comput Biol. 2000 Feb-Apr;7(1-2):203-14. doi: 10.1089/10665270050081478. PMID: 10890397.
Edgar RC. Search and clustering orders of magnitude faster than BLAST.
Bioinformatics. 2010 Oct 1;26(19):2460-1. doi: 10.1093/bioinformatics/btq461. Epub 2010 Aug 12. PubMed PMID: 20709691.
3. Designations used in the taxonomy:
1) Taxonomy levels are indicated by these prefixes:
k__: domain/kingdom
p__: phylum
c__: class
o__: order
f__: family
g__: genus
s__: species
Example:
k__Bacteria;p__Firmicutes;c__Clostridia;o__Clostridiales;f__Lachnospiraceae;g__Blautia;s__faecis
2) Unique level identified – known species:
k__Bacteria;p__Firmicutes;c__Clostridia;o__Clostridiales;f__Lachnospiraceae;g__Roseburia;s__hominis
The above example shows some reads match to a single species (all levels are unique)
3) Non-unique level identified – known species:
k__Bacteria;p__Firmicutes;c__Clostridia;o__Clostridiales;f__Lachnospiraceae;g__Roseburia;s__multispecies_spp123_3
The above example “s__multispecies_spp123_3” indicates certain reads equally match to 3 species of the
genus Roseburia; the “spp123” is a temporally assigned species ID.
k__Bacteria;p__Firmicutes;c__Clostridia;o__Clostridiales;f__Lachnospiraceae;g__multigenus;s__multispecies_spp234_5
The above example indicates certain reads match equally to 5 different species, which belong to multiple genera.;
the “spp234” is a temporally assigned species ID.
4) Unique level identified – unknown species, potential novel species:
k__Bacteria;p__Firmicutes;c__Clostridia;o__Clostridiales;f__Lachnospiraceae;g__Roseburia;s__ hominis_nov_97%
The above example indicates that some reads have no match to any of the reference sequences with
sequence identity ≥ 98% and percent coverage (alignment length) ≥ 98% as well. However this groups
of reads (actually the representative read from a de novo OTU) has 96% percent identity to
Roseburia hominis, thus this is a potential novel species, closest to Roseburia hominis.
(But they are not the same species).
5) Multiple level identified – unknown species, potential novel species:
k__Bacteria;p__Firmicutes;c__Clostridia;o__Clostridiales;f__Lachnospiraceae;g__Roseburia;s__ multispecies_sppn123_3_nov_96%
The above example indicates that some reads have no match to any of the reference sequences
with sequence identity ≥ 98% and percent coverage (alignment length) ≥ 98% as well.
However this groups of reads (actually the representative read from a de novo OTU)
has 96% percent identity equally to 3 species in Roseburia. Thus this is no single
closest species, instead this group of reads match equally to multiple species at 96%.
Since they have passed chimera check so they represent a novel species. “sppn123” is a
temporary ID for this potential novel species.
4. The taxonomy assignment algorithm is illustrated in this flow char below:
Read Taxonomy Assignment - Result Summary *
Code
Category
MPC=0% (>=1 read)
MPC=0.01%(>=242 reads)
A
Total reads
2,437,068
2,437,068
B
Total assigned reads
2,426,275
2,426,275
C
Assigned reads in species with read count < MPC
0
46,180
D
Assigned reads in samples with read count < 500
0
0
E
Total samples
98
98
F
Samples with reads >= 500
98
98
G
Samples with reads < 500
0
0
H
Total assigned reads used for analysis (B-C-D)
2,426,275
2,380,095
I
Reads assigned to single species
1,567,568
1,559,815
J
Reads assigned to multiple species
153,490
150,959
K
Reads assigned to novel species
705,217
669,321
L
Total number of species
1,391
438
M
Number of single species
250
140
N
Number of multi-species
70
26
O
Number of novel species
1,071
272
P
Total unassigned reads
10,793
10,793
Q
Chimeric reads
1,070
1,070
R
Reads without BLASTN hits
341
341
S
Others: short, low quality, singletons, etc.
9,382
9,382
A=B+P=C+D+H+Q+R+S
E=F+G
B=C+D+H
H=I+J+K
L=M+N+O
P=Q+R+S
* MPC = Minimal percent (of all assigned reads) read count per species, species with read count < MPC were removed.
* Samples with reads < 500 were removed from downstream analyses.
* The assignment result from MPC=0.1% was used in the downstream analyses.
Read Taxonomy Assignment - ASV Species-Level Read Counts Table
This table shows the read counts for each sample (columns) and each species identified based on the ASV sequences.
The downstream analyses were based on this table.
The species listed in the table has full taxonomy and a dynamically assigned species ID specific to this report.
When some reads match with the reference sequences of more than one species equally (i.e., same percent identiy and alignmnet coverage),
they can't be assigned to a particular species. Instead, they are assigned to multiple species with the species notaton
"s__multispecies_spp2_2". In this notation, spp2 is the dynamic ID assigned to these reads that hit multiple sequences and the "_2"
at the end of the notation means there are two species in the spp2.
You can look up which species are included in the multi-species assignment, in this table below:
Another type of notation is "s__multispecies_sppn2_2", in which the "n" in the sppn2 means it's a potential novel species because all the reads in this species
have < 98% idenity to any of the reference sequences. They were grouped together based on de novo OTU clustering at 98% identity cutoff. And then
a representative sequence was chosed to BLASTN search against the reference database to find the closest match (but will still be < 98%). This representative
sequence also matched equally to more than one species, hence the "spp" was given in the label.
In ecology, alpha diversity (α-diversity) is the mean species diversity in sites or habitats at a local scale.
The term was introduced by R. H. Whittaker[5][6] together with the terms beta diversity (β-diversity)
and gamma diversity (γ-diversity). Whittaker's idea was that the total species diversity in a landscape
(gamma diversity) is determined by two different things, the mean species diversity in sites or habitats
at a more local scale (alpha diversity) and the differentiation among those habitats (beta diversity).
Diversity measures are affected by the sampling depth. Rarefaction is a technique to assess species richness from the results of sampling. Rarefaction allows
the calculation of species richness for a given number of individual samples, based on the construction
of so-called rarefaction curves. This curve is a plot of the number of species as a function of the
number of samples. Rarefaction curves generally grow rapidly at first, as the most common species are found,
but the curves plateau as only the rarest species remain to be sampled [7].
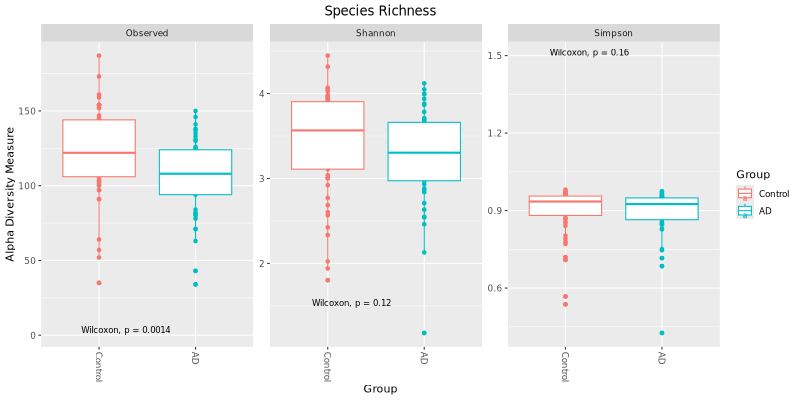
The two main factors taken into account when measuring diversity are richness and evenness.
Richness is a measure of the number of different kinds of organisms present in a particular area.
Evenness compares the similarity of the population size of each of the species present. There are
many different ways to measure the richness and evenness. These measurements are called "estimators" or "indices".
Below is a diversity of 3 commonly used indices showing the values for all the samples (dots) and in groups (boxes) at the species level.
Printed on each graph is the statistical significance p values of the difference between the groups.
The significance is calculated using either Kruskal-Wallis test or the Wilcoxon rank sum test, both are non-parametric methods (since
microbiome read count data are considered non-normally distributed) for testing
whether samples originate from the same distribution (i.e., no difference between groups). The Kruskal-Wallis test is used to compare three or more
independent groups to determine if there are statistically significant differences between their medians. The Wilcoxon Rank Sum test, also known as
the Mann-Whitney U test, is used to compare two independent groups to determine if there is a significant difference between their distributions.
The p-value is shown on the top of each graph. A p-value < 0.05 is considered statistically significant between/among the test groups.
Alpha Diversity Box Plots for All Groups - Species Level
Alpha Diversity Box Plots for Individual Comparisons at Species level
Beta diversity compares the similarity (or dissimilarity) of microbial profiles between different
groups of samples. There are many different similarity/dissimilarity metrics [8].
In general, they can be quantitative (using sequence abundance, e.g., Bray-Curtis or weighted UniFrac)
or binary (considering only presence-absence of sequences, e.g., binary Jaccard or unweighted UniFrac).
They can be even based on phylogeny (e.g., UniFrac metrics) or not (non-UniFrac metrics, such as Bray-Curtis, etc.).
For microbiome studies, species profiles of samples can be compared with the Bray-Curtis dissimilarity,
which is based on the count data type. The pair-wise Bray-Curtis dissimilarity matrix of all samples can then be
subject to either multi-dimensional scaling (MDS, also known as PCoA) or non-metric MDS (NMDS).
MDS/PCoA is a
scaling or ordination method that starts with a matrix of similarities or dissimilarities
between a set of samples and aims to produce a low-dimensional graphical plot of the data
in such a way that distances between points in the plot are close to original dissimilarities.
NMDS is similar to MDS, however it does not use the dissimilarities data, instead it converts them into
the ranks and use these ranks in the calculation.
In our beta diversity analysis, Bray-Curtis dissimilarity matrix was first calculated and then plotted by the PCoA and
NMDS separately. Below are beta diveristy results for all groups together, at the Species level:
NMDS and PCoA Plots for All Groups - Species Level
The above PCoA and NMDS plots are based on count data. The count data can also be transformed into centered log ratio (CLR)
for each species. The CLR data is no longer count data and cannot be used in Bray-Curtis dissimilarity calculation. Instead
CLR can be compared with Euclidean distances. When CLR data are compared by Euclidean distance, the distance is also called
Aitchison distance.
Below are the NMDS and PCoA plots of the Aitchison distances of the samples at the Species level:
NMDS and PCoA Plots for Individual Comparisons at Species level
16S rRNA next generation sequencing (NGS) generates a fixed number of reads that reflect the proportion of different
species in a sample, i.e., the relative abundance of species, instead of the absolute abundance.
In Mathematics, measurements involving probabilities, proportions, percentages, and ppm can all
be thought of as compositional data. This makes the microbiome read count data “compositional”
(Gloor et al, 2017). In general, compositional data represent parts of a whole which only
carry relative information [9].
The problem of microbiome data being compositional arises when comparing two groups of samples for
identifying “differentially abundant” species. A species with the same absolute abundance between two
conditions, its relative abundances in the two conditions (e.g., percent abundance) can become different
if the relative abundance of other species change greatly. This problem can lead to incorrect conclusion
in terms of differential abundance for microbial species in the samples.
When studying differential abundance (DA), the current better approach is to transform the read count
data into log ratio data. The ratios are calculated between read counts of all species in a sample to
a “reference” count (e.g., mean read count of the sample). The log ratio data allow the detection of DA
species without being affected by percentage bias mentioned above
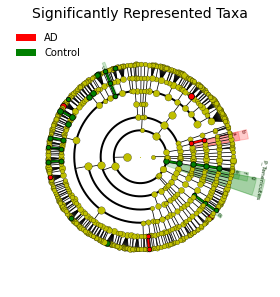
In this report, a compositional DA analysis tool “ANCOM” (analysis of composition of microbiomes)
was used [10]. ANCOM transforms the count data into log-ratios and thus is more suitable for comparing
the composition of microbiomes in two or more populations. "ANCOM" generates a table of features with
W-statistics and whether the null hypothesis is rejected. The “W” is the W-statistic, or number of
features that a single feature is tested to be significantly different against. Hence the higher the "W"
the more statistical sifgnificant that a feature/species is differentially abundant.
References:
Gloor GB, Macklaim JM, Pawlowsky-Glahn V, Egozcue JJ. Microbiome Datasets Are Compositional: And This Is Not Optional. Front Microbiol.
2017 Nov 15;8:2224. doi: 10.3389/fmicb.2017.02224. PMID: 29187837; PMCID: PMC5695134.
Mandal S, Van Treuren W, White RA, Eggesbø M, Knight R, Peddada SD. Analysis of composition of
microbiomes: a novel method for studying microbial composition. Microb Ecol Health Dis.
2015 May 29;26:27663. doi: 10.3402/mehd.v26.27663. PMID: 26028277; PMCID: PMC4450248.
Starting with version V1.2, we include the results of ANCOM-BC (Analysis of Compositions of
Microbiomes with Bias Correction) (Lin and Peddada 2020) [11]. ANCOM-BC is an updated version of "ANCOM" that:
(a) provides statistically valid test with appropriate p-values,
(b) provides confidence intervals for differential abundance of each taxon,
(c) controls the False Discovery Rate (FDR),
(d) maintains adequate power, and
(e) is computationally simple to implement.
The bias correction (BC) addresses a challenging problem of the bias introduced by differences in
the sampling fractions across samples. This bias has been a major hurdle in performing DA analysis of microbiome data.
ANCOM-BC estimates the unknown sampling fractions and corrects the bias induced by their differences among samples.
The absolute abundance data are modeled using a linear regression framework.
Starting with version V1.43, ANCOM-BC2 is used instead of ANCOM-BC, So that multiple pairwise directional test can be performed (if there are more than two gorups in a comparison).
When performing pairwise directional test, the mixed directional false discover rate (mdFDR) is taken into account. The mdFDR
is the combination of false discovery rate due to multiple testing, multiple pairwise comparisons, and directional tests within
each pairwise comparison. The mdFDR is adopted from (Guo, Sarkar, and Peddada 2010 [12]; Grandhi, Guo, and Peddada 2016 [13]). For more detail
explanation and additional features of ANCOM-BC2 please see author's documentation.
References:
Lin H, Peddada SD. Analysis of compositions of microbiomes with bias correction.
Nat Commun. 2020 Jul 14;11(1):3514. doi: 10.1038/s41467-020-17041-7.
PMID: 32665548; PMCID: PMC7360769.
Guo W, Sarkar SK, Peddada SD. Controlling false discoveries in multidimensional directional decisions, with applications to gene expression data on ordered categories. Biometrics. 2010 Jun;66(2):485-92. doi: 10.1111/j.1541-0420.2009.01292.x. Epub 2009 Jul 23. PMID: 19645703; PMCID: PMC2895927.
Grandhi A, Guo W, Peddada SD. A multiple testing procedure for multi-dimensional pairwise comparisons with application to gene expression studies. BMC Bioinformatics. 2016 Feb 25;17:104. doi: 10.1186/s12859-016-0937-5. PMID: 26917217; PMCID: PMC4768411.
LEfSe (Linear Discriminant Analysis Effect Size) is an alternative method to find "organisms, genes, or
pathways that consistently explain the differences between two or more microbial communities" (Segata et al., 2011) [14].
Specifically, LEfSe uses rank-based Kruskal-Wallis (KW) sum-rank test to detect features with significant
differential (relative) abundance with respect to the class of interest. Since it is rank-based, instead of proportional based,
the differential species identified among the comparison groups is less biased (than percent abundance based).
Reference:
Segata N, Izard J, Waldron L, Gevers D, Miropolsky L, Garrett WS, Huttenhower C. Metagenomic biomarker discovery and explanation. Genome Biol. 2011 Jun 24;12(6):R60. doi: 10.1186/gb-2011-12-6-r60. PMID: 21702898; PMCID: PMC3218848.
To analyze the co-occurrence or co-exclusion between microbial species among different samples, network correlation
analysis tools are usually used for this purpose. However, microbiome count data are compositional. If count data are normalized to the total number of counts in the
sample, the data become not independent and traditional statistical metrics (e.g., correlation) for the detection
of specie-species relationships can lead to spurious results. In addition, sequencing-based studies typically
measure hundreds of OTUs (species) on few samples; thus, inference of OTU-OTU association networks is severely
under-powered. We provide the network association result with SparCC (Sparse Correlations for Compositional data)(Friedman & Alm 2012), which
is a method for inferring correlations from compositional data. SparCC estimates the linear Pearson correlations between
the log-transformed components.
The results of this analysis are for research purpose only. They are not intended to diagnose, treat, cure, or prevent any disease. Forsyth and FOMC
are not responsible for use of information provided in this report outside the research area.












{kind=link}
{kind=link}
{kind=link}